


剪辑|冷猫

自从 2015 年 ResNet 出身以来,这种「将输入径直加到输出上」的浮浅逻辑,统率了险些所有神经网罗架构。
但就在刚刚,沿用了十年的残差机制「升级」了。随橙想呢,替代步伐真的是「神圣力机制」。

就连 OpenAI 「推理模子之父」,主导了 o1/o3 系列、Codex 编程模子及 GPT-4 的 STEM 才略确立的 Jerry Tworek 齐深受这一论文启发,认为应当再行想考之前的一切,「深度学习 2.0」的时期行将到来。
这篇颠覆传统残差伙同机制的责任来自 Kimi 团队,发布了一项重磅时间求教:Attention Residuals ,该步伐旨在通过对前序层进行学习到的、依赖输入的神圣力机制,来取代圭臬的深度递归。

论文标题:Attention Residuals
相貌伙同:https://github.com/MoonshotAI/Attention-Residuals
时刻与深度的对偶
要交融 Attention Residuals 是在作念什么,咱们得先看传统的残差伙同 y = x + f (x) 出了什么问题。
在大模子向更深、更强演进的历程中,这种残差的加法机制带来了两个反作用:
1. 信息稀释: 残差伙同汲取固定单元权重的均匀团员,导致浅层特征在向深层传递时,其相对孝敬度随深度线性衰减。这种「信息稀释」时势戒指了深层网罗对底层原始示意的径直应用才略。跟着层数加多,第一层的信息传到第一百层时,依然被背面九十九层的信息层层冲淡。
2. 荫藏现象爆炸:为了在赓续累加的残差流中保管信号强度,深层模块通常需要输出模长更大的激活值。这种隐现象的无序膨胀不仅松弛了数值清爽性,还导致梯度散播不均,加多了超大鸿沟模子历练欺压的难度,径直导致了历练的不清爽性。
本文的天才之处在于,发现模子的「深度」其实即是另一种步地的「时刻」。
论文作家之一的 Yulun Du 赤诚说念出了该论文的中枢想想:将神圣力旋转 90°。
Attention Residuals (AttnRes) 由此出身:为每一层配备了一个「智能筛选器」。每一层齐会发出一个 Query,去之前的所有层里寻找最联系的特征,并按需分拨权重进行团员。

神圣力残差
表面重构:竣工的神圣力残差
传统的残差伙同(ResNet)本体上是深度递归:它像 RNN 一样,把往时所有层的信息固执地 「压缩」进一个乞降现象中。

中枢改进: 既然 Transformer 用神圣力机制取代了 RNN,管制了长序列的淡忘问题;那么 AttnRes 就在深度上取代了残差累加。
数学收场: 每一层不再是浮浅地加向前一层,而是发出一个可学习的 Query,去和之前所有层产生的 Key 作念匹配。
Softmax 权重: 通过 Softmax 归一化,模子不错 「挑选」 出对我方最有效的某几层。比如第 50 层不错径直索取第 2 层的特征,权重占比不错高达 0.8,而无须挂念被中间的 48 层稀释。
工程落地:Block AttnRes 的分块战略

成果遗迹: 本质发现,即便模子有上百层,惟有分袂红 N≈8 个块,就能获取绝大部分性能增益。
复杂度骤降: 内存支拨从随层数 L 增长,降到了随块数增长。这意味着你不错用极小的代价(推理蔓延加多2%),获取一个 「更灵巧」 的深层网罗。
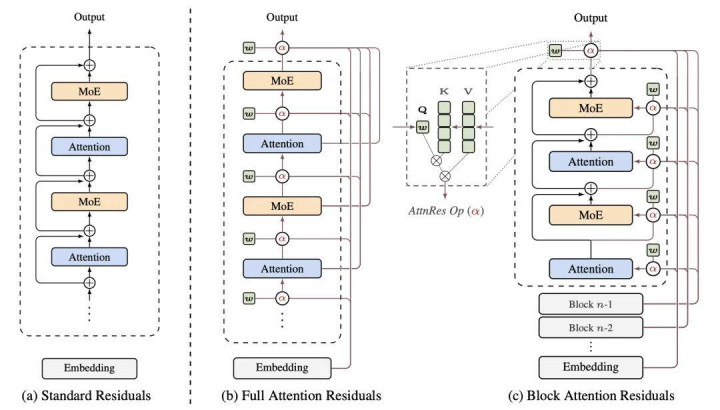
图 1:Attention Residuals 概览:(a) 圭臬残差(Standard Residuals): 汲取均匀加法累加的传统残差伙同方式。(b) 全量神圣力残差(Full AttnRes): 每一层齐通过学习到的神圣力权重,有采选地团员之前所有层的输出。(c) 块神圣力残差(Block AttnRes): 将各层分袂为几许个「块」,将内存支拨从 O (Ld) 裁汰至 O (Nd)。
战果:1.25 倍的「诡计杠杆」
证据论文信息,本质架构与 Kimi Linear 足够一致,金年会(JinNianHui)体育这是一种革职 Moonlight / DeepSeek-V3 遐想的夹杂大家模子(MoE) Transformer。独一的修改是在残差伙同中加入了 AttnRes;模子深度、荫藏维度、大家路由和 MLP 结构等其他组件均保握不变。
磋磨团队测试了五种模子鸿沟,并为每种鸿沟历练了三个变体:PreNorm 基准模子、全量 AttnRes 以及约 8 个块的 Block AttnRes。
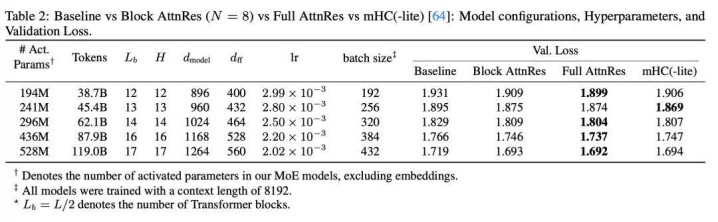
下图展示了拟合后的鸿沟化弧线。
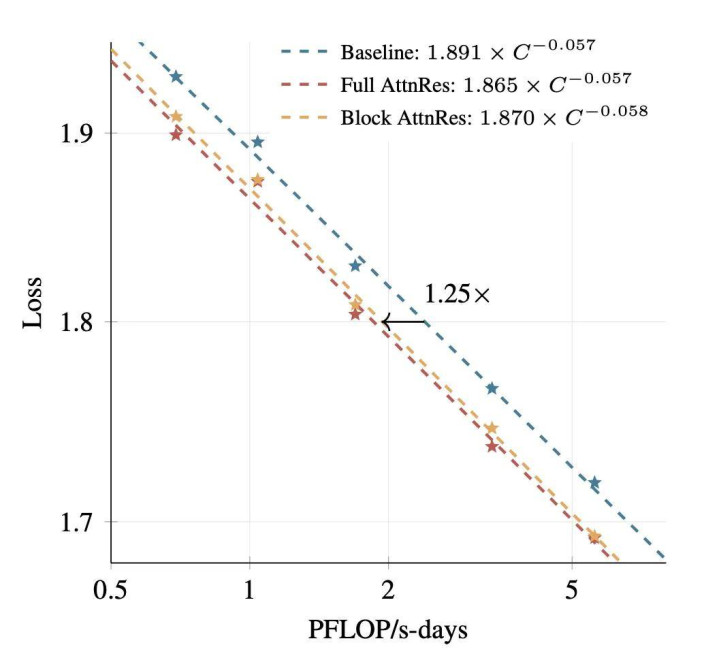
三个变体的斜率相似,但 AttnRes 在所有这个词诡计范围内一致收场了更低的损耗(Loss)。基于拟合弧线,在 5.6 PFLOP/s-days 的诡计量下,Block AttnRes 的损耗为 1.692,而基准模子为 1.714,这相等于 1.25 倍的诡计上风(Compute Advantage)。跟着模子鸿沟增大,Full 与 Block 变体之间的差距在松开。
磋磨团队的最大模子基于 Kimi Linear 48B 建树:27 个 Transformer 块(共 54 层),在 256 个路由大家中激活 8 个,外加 1 个分享大家,总参数 48B,激活参数 3B。该模子汲取 Block AttnRes,每块 6 层,共产生 9 个块外加 1 个 Token 镶嵌,造成 10 个深度主义的起原。
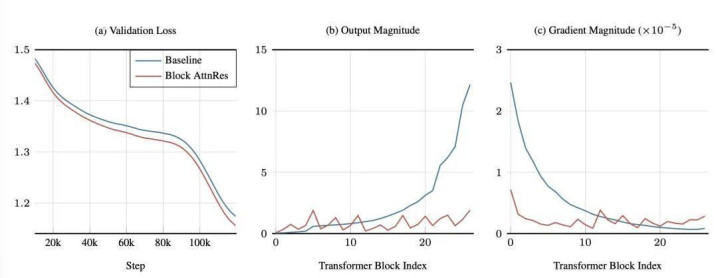
上图展示了模子在 1T token 历练历程中的动态变化:
考证损耗: AttnRes 在所有这个词历练历程中恒久保握较低的考证损耗,尤其在衰减(Decay)阶段差距进一步拉大。
输出量级: 基准模子遭遇 PreNorm 稀释问题:跟着隐现象量级随深度单调增长,深层网罗被动从固定缩放的归一化输入中学习越来越大的输出,以保管影响力。而 Block AttnRes 将这种增长戒指在每个块内,通过块鸿沟的采选性团员重置了累加历程,呈现出有界的周期性模式。
梯度量级: 在所有残差权重固定为 1 的基准模子中,梯度流在深度上的散播极不均匀,导致早期层梯渡过大。Block AttnRes 的可学习 Softmax 权重引入了起原之间的竞争,从而收场了权臣更均匀的梯度散播。
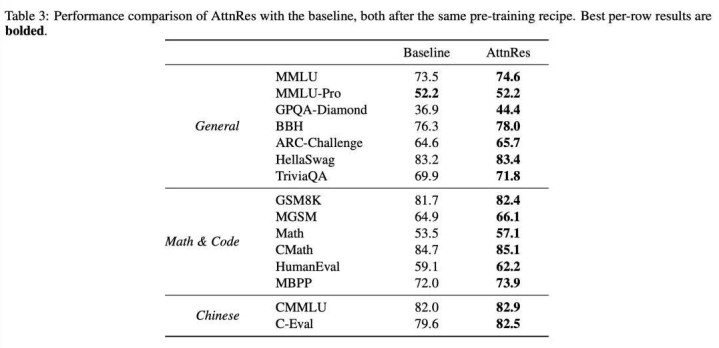
下贱性能施展: 如上表所示,Block AttnRes 在所有评测任务中均达到或逾越了基准模子。
普及权臣的任务: 在多步推理任务中普及尤为隆起,如 GPQA-Diamond (+7.5)、Minerva Math (+3.6) 以及代码生成 HumanEval (+3.1)。
学问类任务: MMLU (+1.1) 和 TriviaQA (+1.9) 也展现了适应的普及。
数据给出了最有劲的说明注解:
诡计成果: 达到一样的性能,AttnRes 比拟传统残差从简了约 20% 的诡计量(1.25x 上风)。
逻辑推理: 在数学、代码等硬核任务上普及权臣。举例,在极难的 GPQA-Diamond 测试中,性能普及了 7.5 分。
清爽性: 成功扼制了荫藏现象的数值爆炸,让深层网罗依然能保握「慎重」和「高效」。
转头:RethinkImagine
用更高维的视角看基础架构的磋磨,时刻和空间齐是叠加的。
这篇论文「将神圣力旋转 90°」的想想,似乎带给 Karpathy 一些启示和想考。
ResNet 的残差流是信息在不同空间深度上的传递。SGD (当场梯度着落)的权重流是信息在不同期间维度上的传递。
磋磨团队合计 ResNet 的加法太朴素了,是以提倡用 Attention 来筛选往时每一层的输出。 既然 SGD 亦然 ResNet,「Attention is All You Need」,那咱们为什么不行在优化器里也加上 Attention?
爱游戏体育APP官方网站下载架构的人命力,通常来自于对惯性的反想。
当咱们回及其去注视那些基础架构,粗略就能在往时的故纸堆中,发现更多通往异日的灭亡结合。
更多信息金年会官网首页入口,请参阅原论文。
 备案号:
备案号: